FITRAH.SCH.ID – Ketika mengunjungi sebuah situs pengelola jurnal, pernah nggak kita terbayang untuk mendownload seluruh file tanpa harus manual klik satu per satu?. Ya meskipun sebenarnya lebih enak membaca langsung di web, dalam beberapa kondisi, kita membutuhkan file artikel tersebut untuk diimport pada aplikasi pengelola sitasi.
Olehkarena itu, pada artikel ini kita akan membahas bagaimana “Cara Mendownload Seluruh File Artikel pada Website OJS Pengelola Jurnal dalam 5 Menit”.
Sekarang bukan zamannya “manual”, banyak tools yang bisa kita gunakan untuk “otomasi” pekerjaan kita. Nah, kita bahas satu diantaranya.
Daftar Isi
Jika Anda membaca tulisan ini, berarti Anda telah tertarik dengan topik yang dibahas. Meskipun judulnya terkesan “clickbait”, metode yang akan dijelaskan di sini benar-benar dapat membantu kamu mengunduh artikel jurnal dengan lebih efisien. Waktu yang dibutuhkan? Tergantung pada kecepatan internet dan perangkat Anda, namun dalam kondisi ideal, proses ini dapat diselesaikan dalam waktu sekitar 5 menit.
Pada kesempatan kali ini, saya akan berbagi pengalaman tentang cara mendownload seluruh artikel pada sebuah website OJS secara otomatis menggunakan bantuan script Python.
Target Output
- Memudahkan Pengunduhan File Jurnal Tulisan ini membahas bagaimana metode membuat script otomasi menggunakan python, jadi kamu tidak perlu lagi membuka dan mengunduh setiap artikel satu per satu. Langsung otomatis.
- Memperkaya Materi dan Referensi Pengetahuan Dengan memiliki banyak artikel jurnal yang terhubung dalam aplikasi sitasi, tentu dapat memperluas wawasan dan mendukung penelitian atau studi. Biasanya, kita perlu banget untuk melakukan sitasi pada artikel jurnal kampus yang belum banyak terindeks di mesin pencari ataupun aplikasi sitasi, jadi kita harus menginputkannya secara manual.
- Membuat Script Otomatis dengan Bantuan AI Tujuan lain dari tulisan ini adalah praktik pembuatan script menggunakan AI. Harapannya, tanpa keahlian pemrograman yang mendalam pun kita tetap bisa membuat program yang powerfull.
- Menguji Keamanan Website Jurnal Nah, dengan menerapkan metode tulisan ini, kita bisa menguji dan mengevaluasi tingkat keamanan platform OJS terhadap aktivitas scraping. Sederhananya, seandainya banyak orang yang melakukan hal yang sama, tentu performa website akan turun. Dengan menerapkan metode ini, kita bisa tau apakah website kita aman atau tidak.
How it Works
Metode ini dilakukan melalui beberapa tahap sistematis untuk memastikan proses pengunduhan berjalan efektif. Berikut penjelasan lengkapnya:
Tahap 1: Analisis Alur dan Struktur Website
Sebelum membuat script, pahami terlebih dahulu alur navigasi website OJS yang dituju. Umumnya, platform OJS memiliki struktur sebagai berikut:
- Halaman Archive Berisi daftar terbitan jurnal (issue) yang tersedia. Contoh URL:
<https://domain.ac.id/index.php/namajurnal/issue/archive> - Halaman Artikel per Terbitan Setiap terbitan memiliki halaman khusus yang memuat daftar artikel. Contoh URL:
<https://domain.ac.id/index.php/namajurnal/issue/view/1739> - Halaman Detail per Terbitan Setiap artikel memiliki URL dengan endpoint
/view/untuk menampilkan daftar isi jurnal di setiap terbitan. Pada halaman ini, juga ada tombol PDF untuk melihat file. Contoh:<https://domain.ac.id/index.php/namajurnal/article/view/1739> - Halaman Detail Artikel Ketika kita klik tombol PDF pada halaman detail per terbitan sebelumnya. Maka kita akan diarahkan ke halaman view artikel. Setiap artikel memiliki URL dengan endpoint
/view/untuk pratinjau abstrak atau metadata. Contoh:<https://domain.ac.id/index.php/namajurnal/article/view/54566/13756> - Link Download Artikel Uniknya, kita juga bisa mendownload artikel dengan mengganti endpoint
/view/menjadi endpoint/download/. Contoh:Awal : <https://domain.ac.id/index.php/namajurnal/view/54566/13756> Download : <https://domain.ac.id/index.php/namajurnal/download/54566/13756>
Tahap 2: Identifikasi Endpoint Penting
Endpoint adalah jalur URL yang digunakan untuk mengakses data tertentu. Pada OJS, dua endpoint krusial perlu dicatat:
- Endpoint Pratinjau Artikel
/view/{id_jurnal}/{id_artikel} - Endpoint Unduhan Artikel
/download/{id_jurnal}/{id_artikel}
Catatan:
- Pola URL OJS umumnya konsisten.
Tahap 3: Pembuatan Script Python
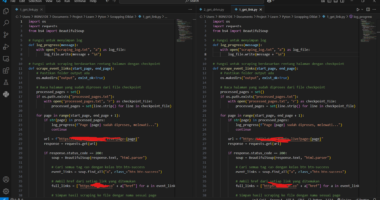
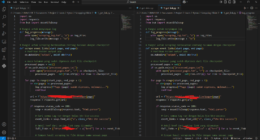
Setelah memahami struktur website dan endpoint, langkah selanjutnya adalah membuat script otomatis dengan bantuan AI (misalnya ChatGPT). Berikut contoh implementasinya bisa cek di repository Strategi Belajar ID.
Intinya, dalam script python tersebut kita akan melakukan :
- Langkah 1: Script mengakses halaman archive untuk mengumpulkan semua URL terbitan.
- Langkah 2: Setiap terbitan dibuka untuk mengekstrak URL melihat artikel yang ada di dalamnya.
- Langkah 3: URL pratinjau artikel (
/view/) diubah menjadi URL unduhan (/download/), lalu file PDF diunduh dan disimpan. - Langkah 4: Kita buat agar script juga mencatata log agar ketika script dijalankan kembali, tidak dari awal.
Pada pembuatan script di chatGPT, pastikan prompt yang diinputkan sesuai dengan alur tersebut agar hasil-nya optimal.
Uji Coba dan Penyimpanan Hasil
- Uji Coba Script
- Pastikan koneksi internet stabil.
- Cari website penyedia jurnal yang hendal kita coba. Kita bisa mendapatkannya dengan mudah di Website Sinta.
- Jalankan script dan pantau prosesnya melalui terminal.
- Simpan Hasil
- File PDF akan tersimpan di folder yang sama dengan script.
- Jika terjadi error, periksa kembali struktur HTML website target atau sesuaikan class yang digunakan (misal:
class_='issue-link').
Batasan Script dan Metode
- Kompatibilitas dengan Tema OJS Script ini hanya dapat digunakan pada platform OJS dengan tema klasik atau modern. Tema yang dimodifikasi secara khusus mungkin memerlukan penyesuaian pada script.
- Contoh Platform yang Telah Diuji Uji coba telah dilakukan pada platform OJS dengan versi 2.4.8.0, 3.3.0.19
- Tidak semua jurnal terproteksiHasil percobaan dari 10 website penyedia jurnal kampus, ada 8 yang berhasil. Artinya, masih banyak website yang tidak membatasi atau mengatur scrapping ataupun bot. Ya semoga tidak ada bot2 berbahaya aja. Hehehe.
Etika Penggunaan
Meskipun script ini dapat mempermudah proses pengunduhan, pastikan kamu memiliki “izin” untuk melakukan aktivitas scraping pada website yang dituju. Selain itu, selalu perhatikan etika dalam penggunaan teknologi untuk menghindari pelanggaran hak cipta atau kebijakan platform.
Dengan demikian, metode ini dapat menjadi solusi praktis bagi kamu yang membutuhkan banyak referensi jurnal dalam waktu singkat.
Selamat mencoba!
Pendidikan itu Harapan
Teknologi itu Jawaban
Fitrah Izul Falaq
Pengembang Teknologi Pembelajaran, Ahli Pertama