
FITRAH.SCH.ID – Dalam era digital yang semakin berkembang, informasi dapat diakses dengan mudah melalui internet. Salah satu metode yang sering digunakan untuk memperoleh data dari sebuah website adalah teknik web scraping.
Web scraping adalah teknik pengambilan data secara otomatis dari suatu website dengan menggunakan skrip atau alat tertentu. Namun, teknik ini juga sering disalahgunakan untuk melakukan cloning atau pembajakan konten suatu website tanpa izin pemiliknya.
Nah, pada artikel ini akan membahas bagaimana teknik clone konten sebuah website dilakukan, dampak negatifnya, serta cara mitigasi dan etika yang harus diperhatikan dalam melakukan scraping.
Teknik clone konten website menggunakan scraping dilakukan dengan cara mengekstrak data dari suatu website dan menyimpannya dalam bentuk yang dapat digunakan kembali.
Daftar Isi

Bagaimana Teknik Clone Konten Website dengan Scraping?
Proses scraping biasanya melibatkan beberapa langkah berikut:
- Mengakses HTML Website
- Scraper mengakses halaman website menggunakan HTTP request untuk mengambil kode sumber HTML.
- Menelusuri Struktur DOM
- Alat scraping kemudian membaca dan memahami struktur Document Object Model (DOM) dari halaman tersebut untuk mengidentifikasi elemen-elemen penting seperti teks, gambar, atau tautan.
- Menyalin dan Menyimpan Konten
- Data yang telah diambil disimpan dalam basis data atau file, lalu ditampilkan kembali di website lain dengan sedikit atau tanpa perubahan.
- Otomatisasi Pengambilan Data
- Beberapa alat scraping dapat melakukan proses ini secara berkala untuk terus memperbarui konten yang dikloning tanpa harus melakukan scraping secara manual.
Bahaya Website yang Mudah di-Scraping
Salah satu dampak buruk dari teknik cloning dengan scraping sering digunakan oleh pihak tertentu untuk meningkatkan traffic tanpa harus bersusah payah membuat konten sendiri.
Website yang rentan terhadap scraping dapat mengalami berbagai dampak negatif, khususnya dalam aspek pembajakan konten. Beberapa bahaya utama meliputi:
- Pencurian Konten untuk Mirroring Website
- Beberapa pihak menggunakan teknik ini untuk membuat salinan identik dari suatu website dengan tujuan membajak trafik dan monetisasi iklan.
- Artikel yang dikloning dapat muncul di website lain tanpa atribusi, mengurangi kredibilitas dan keuntungan pemilik konten asli.
- Dampak terhadap SEO
- Beberapa pelaku menggunakan teknik scraping untuk mengisi website mereka dengan konten dari situs lain agar dapat meningkatkan peringkat pencarian di mesin pencari tanpa perlu membuat konten orisinal.
- Terkadang, beberapa website clone sering kali memiliki reputasi yang baik pada mesin pencari. Sehingga, tidak menutup kemungkinan jika mesin pencari seperti Google dapat menganggap website asli sebagai plagiat jika website kloningan lebih cepat terindeks, yang berakibat pada penurunan peringkat pencarian.
- Penyalahgunaan Data
- Beberapa website mengumpulkan artikel dari berbagai sumber tanpa izin dengan tujuan menjadi agregator informasi, meskipun praktik ini dapat melanggar hak cipta.
- Jika website yang di-scraping memiliki data sensitif, seperti informasi pribadi pengguna, hal ini dapat digunakan untuk tujuan yang tidak etis seperti phishing atau penipuan.
Langkah Mitigasi Clone Website Menggunakan Scraping
Untuk melindungi website dari scraping dan cloning konten, beberapa langkah mitigasi yang dapat diterapkan antara lain:
- Menggunakan Robots.txt
- Mengonfigurasi file
robots.txtuntuk membatasi bot dari mengakses halaman tertentu.
- Mengonfigurasi file
- Memanfaatkan CAPTCHA
- CAPTCHA dapat digunakan untuk mencegah bot otomatis mengakses dan mengekstrak konten dari website.
- Rate Limiting dan Firewall
- Mengatur batas permintaan dari satu IP untuk menghindari pengambilan data secara masif dalam waktu singkat.
- Dynamic Content Rendering
- Menampilkan konten secara dinamis menggunakan JavaScript agar tidak mudah diambil oleh bot scraping berbasis HTML.
- Watermark pada Konten
- Untuk konten visual, seperti gambar atau dokumen, menambahkan watermark dapat membantu mengidentifikasi pencurian konten.
- Memeriksa Aktivitas Pengguna yang Mencurigakan
- Memantau pola akses website dan mendeteksi perilaku yang mencurigakan seperti akses berulang dalam waktu singkat dari IP yang sama.
Easy Way to Clone a Website Content
Saya pernah mencoba melakukan scraping pada sebuah halaman yang menampilkan konten materi hasil webinar maupun pelatihan. Dalam hal ini, saya hanya melakukan pengambilan link materi hasil webinar dari suatu website. Konten tersebut memang dapat langsung diakses secara gratis, tanpa harus mendaftar atau membayar biaya langganan.

Idealnya, kita bisa saja menyalin link materi satu per satu untuk kita simpan. Namun, itu memakan banyak waktu. Nah, disinilah teknik scrapping dibutuhkan. Semakin mudah dan cepat konten suatu website dikumpulkan, disinilah peran etika. Hehehe.
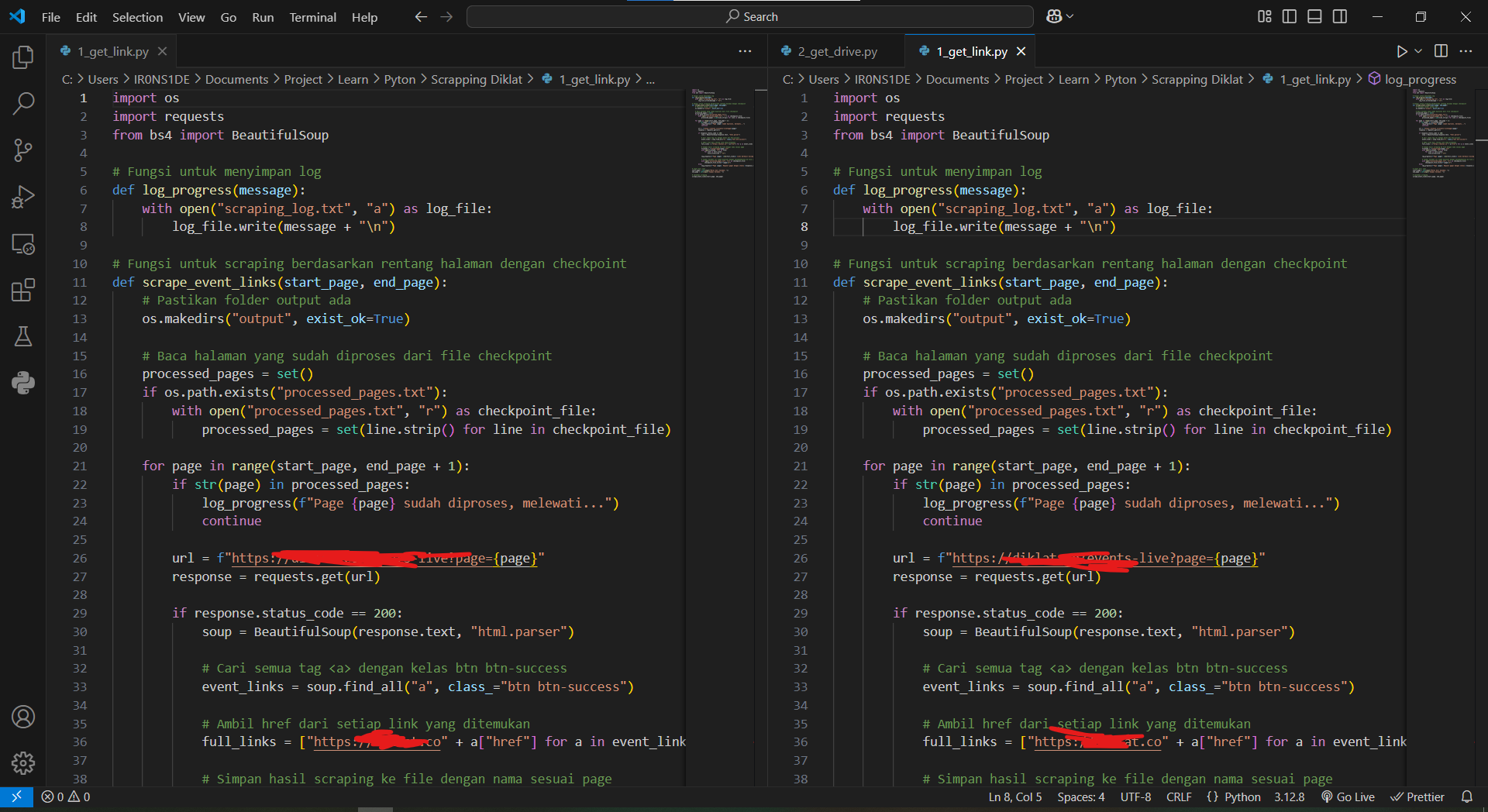
Dari perspektif teknis, proses scraping pada website tersebut sangat mudah karena tidak adanya hambatan keamanan seperti CAPTCHA atau proteksi terhadap bot. Dengan menggunakan script python sederhana, saya dapat dengan cepat mengambil seluruh konten yang telah diposting di website tersebut hanya dengan memasukkan url index materinya.
Setelah berhasil melakukan scraping, data disimpan dalam sebuah database kemudian mempublikasikannya kembali pada website demo. Proses ini menunjukkan betapa mudahnya seseorang dapat menduplikasi konten tanpa izin pemilik asli.
Catatan: Meskipun konten yang tersedia bersifat gratis, tindakan ini tetap menimbulkan dilema etis karena pencurian konten digital dapat merugikan pemilik aslinya. Pemilik website yang menyediakan konten tersebut telah menginvestasikan waktu dan usaha untuk menghasilkan materi berkualitas, namun dengan scraping, semua itu dapat diambil dalam hitungan detik tanpa memberikan penghargaan yang layak.
Etika dalam Melakukan Scrapping Website
Meskipun teknik scraping dapat digunakan secara legal dan bermanfaat, seperti dalam riset data atau pengumpulan informasi publik, tetap ada etika yang harus dipatuhi. Beberapa prinsip etika yang harus diperhatikan diantaranya:
- Mematuhi Kebijakan Website
- Menghormati Hak Cipta
- Tidak Menyalahgunakan Data
- Menggunakan Scraping untuk Tujuan Positif

Insight
Scraping website merupakan praktik yang berpotensi disalahgunakan untuk tujuan yang tidak etis, seperti pembajakan konten dan manipulasi trafik. Website yang rentan terhadap teknik scraping juga dapat mengalami berbagai dampak negatif, mulai dari pencurian konten hingga penyalahgunaan data.
Oleh karena itu, penting bagi pemilik website untuk menerapkan langkah-langkah mitigasi agar terhindar dari scraping ilegal. Di sisi lain, bagi mereka yang menggunakan teknik scraping, penting untuk selalu mengutamakan etika dan memastikan bahwa aktivitas yang dilakukan tidak melanggar hak cipta serta kebijakan website yang bersangkutan.
Dengan demikian, penggunaan scraping dapat tetap memberikan manfaat tanpa merugikan pihak lain. Cheers UP!
Pendidikan itu Harapan
Teknologi itu Jawaban
Fitrah Izul Falaq
Pengembang Teknologi Pembelajaran, Ahli Pertama